


As organisations scale long-context and reasoning-heavy AI workloads, inference costs quickly become the dominant constraint. In Maincode’s latest inference benchmark, we found that moving from public AI APIs to an owned, on-premise AI Token Factory reduced cost per token by up to 87%, enabled 7.7x more token throughput at the same spend.
These gains were achieved using a representative production workload of 8,000 input tokens and 1,000 output tokens per request, typical of summarisation or reasoning over multi-page documents in a business context. The benchmark compared public cloud APIs against on-premise systems, including NVIDIA DGX and Maincode’s MC-X software running on AMD MI355X GPUs.
The results highlight a structural shift in inference economics: at scale, ownership of the inference stack fundamentally outperforms rental-based API models, not just on cost, but on capacity for experimentation and growth.
Challenge: The API Cost Barrier
Public AI APIs are optimised for convenience and elasticity, not for sustainable high-volume inference.
Two structural issues repeatedly show up in real-world deployments:
- Cost explosion at scale: Even moderate daily volumes of long-context inference can translate into six-figure monthly API bills.
- Forced under-utilisation of data: To control costs, teams often restrict high-quality reasoning models to small subsets of their data, leaving most inputs processed with cheaper or less capable approaches.
This creates a tradeoff between financial sustainability and product quality that becomes increasingly difficult to justify as usage grows.
Solution: An On-Premise AI Token Factory
An on-premise AI Token Factory means full ownership and operational control of the hardware and software stack used to run AI models. This shift moves model inference from an OpEx (operating expense) rental model to a CapEx (capital expense) ownership model, dramatically lowering the cost per token in the process.
We compared three deployment methods for a representative workload of 8,000 input tokens and 1,000 output tokens per request, simulating a typical example of summarisation or reasoning over a multi-page transcript:
- Public AI APIs (Azure, AWS, Fireworks, Mistral Platform)
- Nvidia DGX (On-premise, powered by Nvidia B200 GPUs)
- Maincode MC-X Software (On premise, powered by AMD MI355X GPUs)
Result: Cost Per Million Tokens Reduce By Up To 87%
The resulting numbers paint a clear picture: the cost per token drops by up to 87% using an on-premise AI token Factory. This calculation assumes amortisation of the on-premise solution over three years, and includes datacenter cost to ensure a realistic comparison.
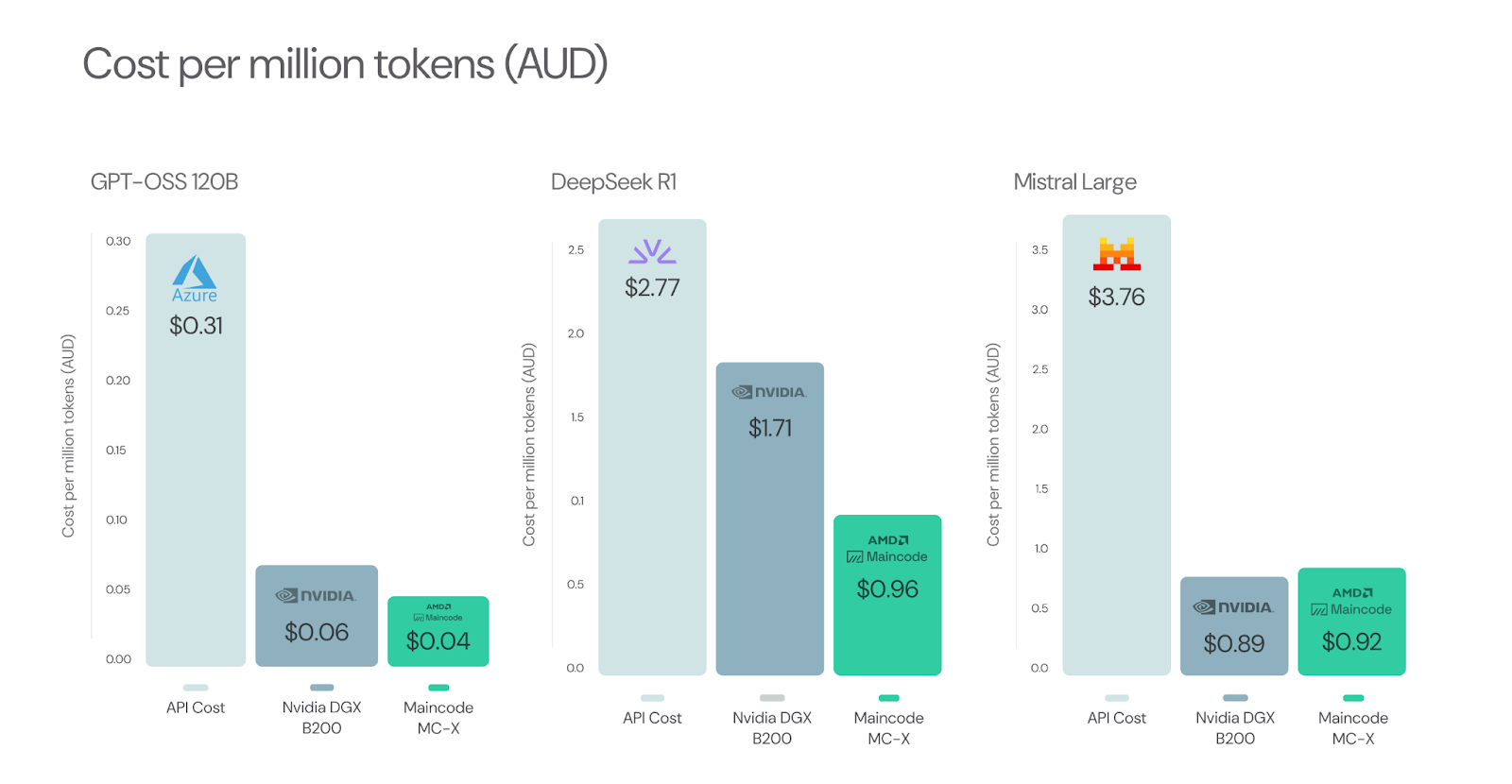
To add, we compared the NVIDIA DGX cluster against our on-prem MC-X software layer running on AMD GPUs. We found that the solutions perform on-par for dense models (e.g. Mistral Large). However, for Mixture of Expert (MoE) models like DeepSeek R1 and GPT-OSS, MC-X further reduces cost by up to 44% compared to the NVIDIA DGX cluster. In other words, the MC-X cluster produces almost twice as many tokens at the same cost compared to NVIDIA DGX.
The ROI of an AI Token Factory
Running AI workloads on the Maincode MC-X solution fundamentally transforms unit economics. When deploying complex, reasoning-heavy workloads, a single MC-X cluster unlocks the capacity to process 100,000 multi-page documents per day.
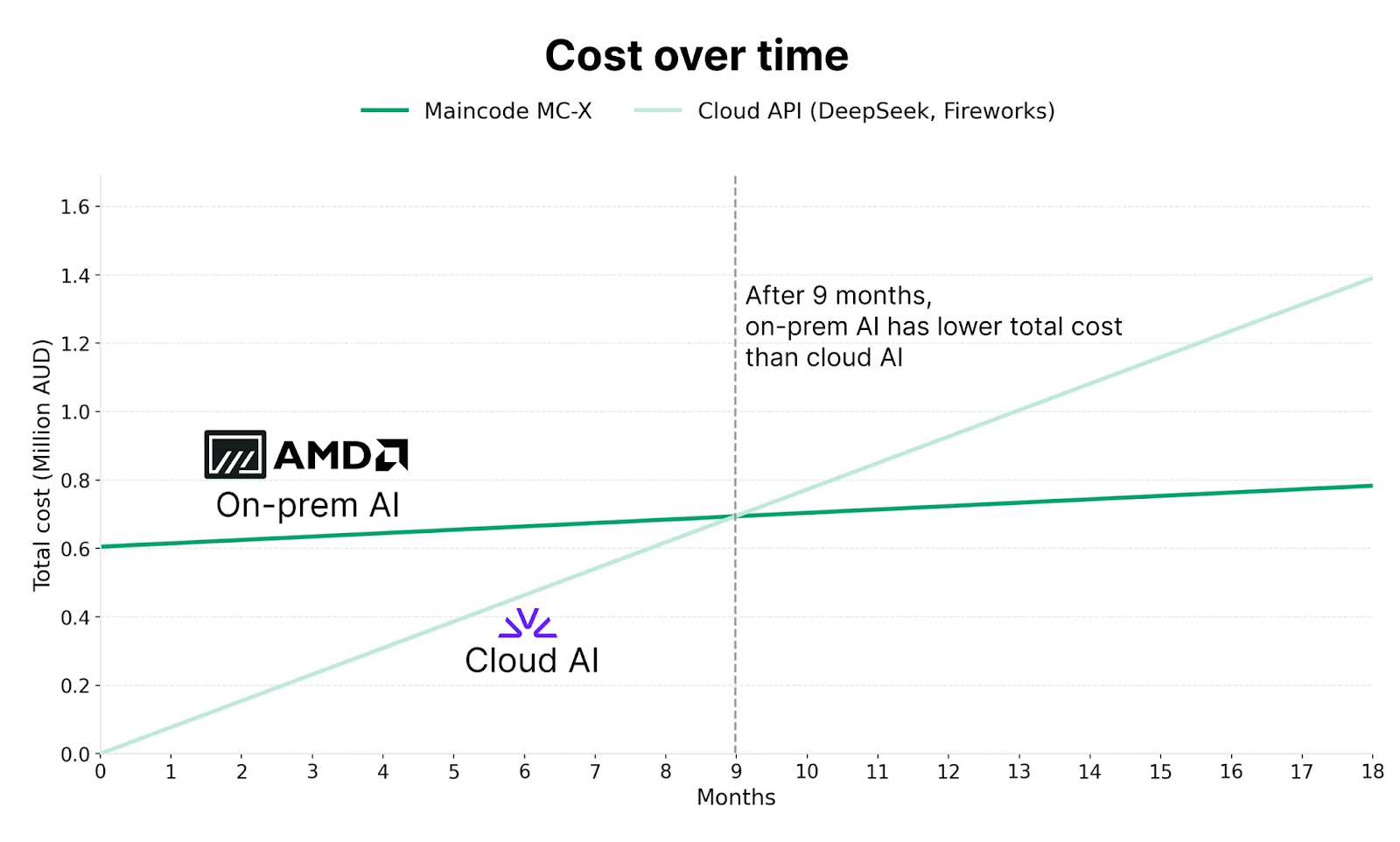
This shift delivers immediate financial impact: monthly operating costs for this particular workload plummets from $77,254 AUD (via public API) to just $26,706 AUD (MC-X) in amortised hardware costs, allowing the hardware investment to fully pay for itself within just 9 months.
The efficiency gains are even more pronounced for less reasoning-heavy generative tasks. For lighter workloads, such as those running the GPT-OSS model, the MC-X compute performance enables processing a significantly larger data volume (500,000 multi-page documents) at only 17.8% utilisation of the system.
Crucially, this creates a massive "Free Capacity" advantage. Because the hardware is owned rather than rented, the remaining ~82% of compute power is available at no marginal cost. This surplus allows experiment with new agents, fine-tune models, run deep background analytics, or scale to 2.5 million daily documents without spending an extra dollar on inference. Faster and cheaper experimentation is ultimately a key success driver for businesses exploring AI automation that actually makes a difference to the bottom line.
Beyond Hardware: The MC-X Advantage
MC-X is a turnkey software layer designed for high-throughput AI factories:
- Turnkey Solution: rapid, optimised deployment of models (DeepSeek, Mistral, Llama, etc.) and standard AI pipelines without complex CUDA/ROCm engineering overhead.
- Granular Monitoring: Real-time visibility into token throughput, thermal performance, and utilisation rates per GPU.
- Security and Governance: Enterprise-grade security and governance ensuring data remains isolated and accessible only to authorised services.
Deploying Maincode’s MC-X powered token factory successfully breaks the unsustainable relationship between user growth and operating costs.
For high-volume AI companies, this case study proves that owning a token factory can dramatically expand an organisation’s capacity for automation, experimentation and innovation.



