


The current frontier in the fast-paced world of AI research is Computer Control Agents or CCA.
OpenAI released Operator and Anthropic its computer use capability. Large language models (LLM) that interact with websites and the apps on our phones like humans do. Vision is enabled via screen captures and actions are mouse clicks, screen touches and keystrokes.
How did we get here?
The AI Revolution
The revolution of language-based AI models started with OpenAI's belief in the scaling hypothesis - that AI models keep improving solely by scaling up the model size and training data. While the research lab released more and more capable generative pre-trained transformer (GPT) models, the gravitas of the new technology only hit the public conscious with the release of ChatGPT in November 2022. ChatGPT combined the previous pre-training advances with instruction fine-tuning and a truly novel user experience in form of the chat interface.
Although the continued scaling of pre-training, fine-tuning via supervision and human feedback and prompting techniques like chain-of-thought yielded some improvements, the next big breakthrough was only achieved by moving to reinforcement learning on problems with verifiable solutions, like mathematics and coding challenges. Again, OpenAI led the way with the release of its o1 reasoning model, which naturally learned to "think" and utilize more compute during inference.
Now, the predominant question in frontier research is how to apply reinforcement learning to domains that are less well-defined, where the solutions are not as easily verifiable. Domains like web browsing and app usage.
At Maincode, we don't believe that OpenAI is on the right track this time. The space of possible actions in typical consumer and enterprise software is limited. Selecting from 200,000 tokens at every inference step is inefficient and invites hallucinations. Invoking models with more than a trillion parameters to click "Contacts" when adding a new contact is costly and slow. Predicting the precise coordinates of the next click with models that struggle to count the number of "r" in the word strawberry seems brittle.
What is the future of CCA?
Reinforcement and Search
We dove deep into the literature of Computer Control Agents, only to learn that most recent research employs pre-trained LLMs, subject to the outlined limitations.
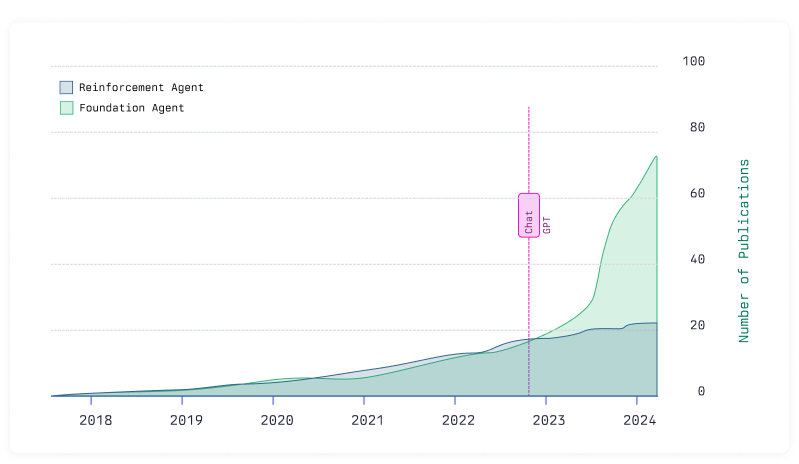
All agents we reviewed, including the ones with custom architectures and trained via reinforcement learning, ingest screen captures and HTML code and predict a single next action. But websites and mobile applications have inherent structure - graphs that can be learned and searched.
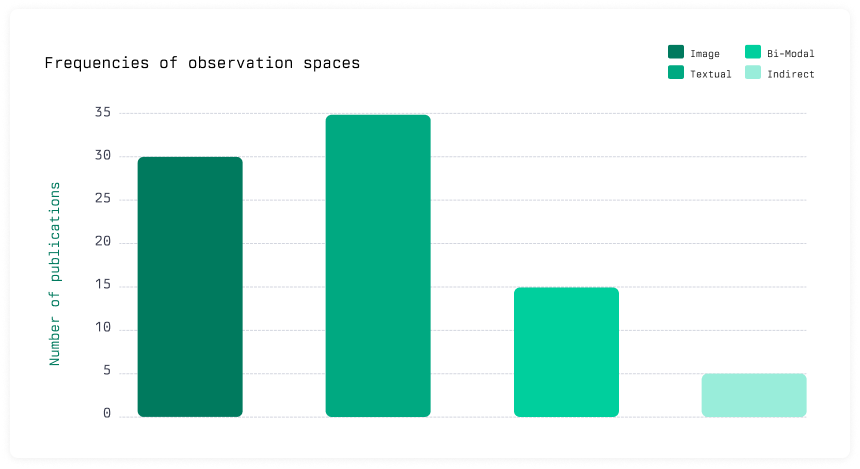
We envision intelligent agents to learn directly and explicitly from experience. Similar to how humans operate, adding Jupiter, Peter and Bob to your contacts should not be 3x the time and cost of adding a single contact.
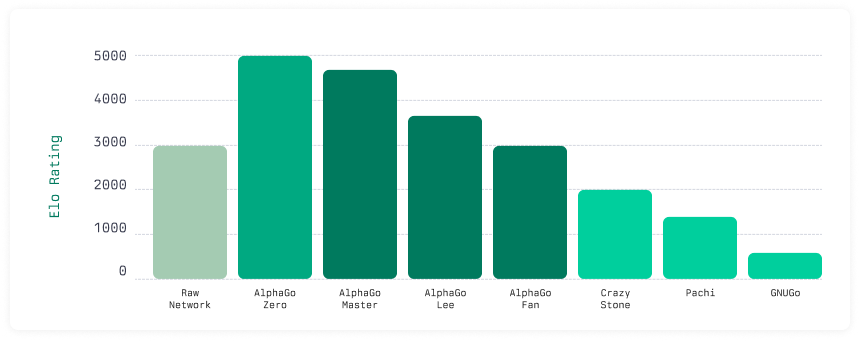
DeepMind's pioneering research on AI for games demonstrated time and time again that agents without search cannot outperform human experts. AlphaGo Zero achieved superhuman performance with a rating of 5185 in the game of Go. Without its search capability, the rating dropped to 3055.
At Maincode, we are training lightweight computer control agents - fast, efficient and inexpensive. Our agents learn how to navigate your software once, not again and again; our agents search for solutions, not guess the next step; and our agents know how to solve problems, not how to write in the style of Shakespeare.
What does that look like in action?
Check out our prototype agent, effortlessly navigating open-source customer relationship management software; exploiting the learned structure where possible; exploring new paths where necessary.
[Sager et al., 2025]: AI Agents for Computer Use: A Review of Instruction-based Computer Control, GUI Automation, and Operator Assistants. arXiv preprint arXiv:2501.16150.
[Silver et al., 2016]: Mastering the game of go without human knowledge. nature, 550(7676), 354-359.



