


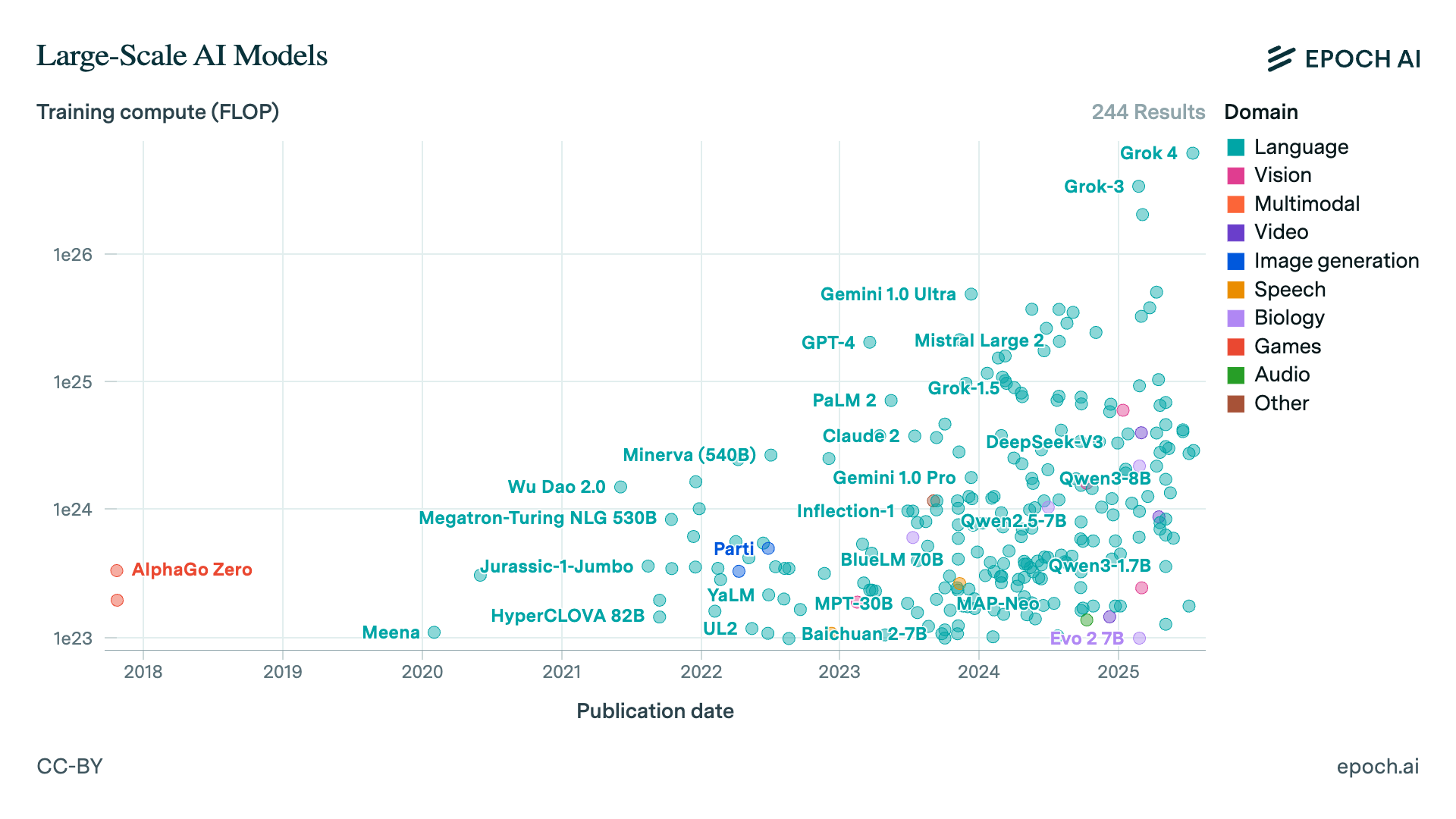
AI progress feels relentless, so relentless it makes nearly impossible to grasp every breakthrough or idea that emerges. There’s no question about AI’s research output or its widespread impact. Training budgets for frontier models have jumped from ≈ 1023 FLOPs in 2017 to ~1026 today, three orders of magnitude in seven years (see Epoch chart). That growth fuels ever-more-powerful models that span language, vision, audio, gaming, and more.
Every morning my feed detonates with technical papers, repos, metrics dashboards, tutorials, blogs, podcasts, conference decks… the manifold repositories of hype. It’s a world of abstractions flowing in every direction, each pitched at a different audience and purpose. As an anxious computational scientist, I oscillate between FOMO, the uncertainty of not knowing and caffeine-fuelled overload.
Making an Intentional Bet
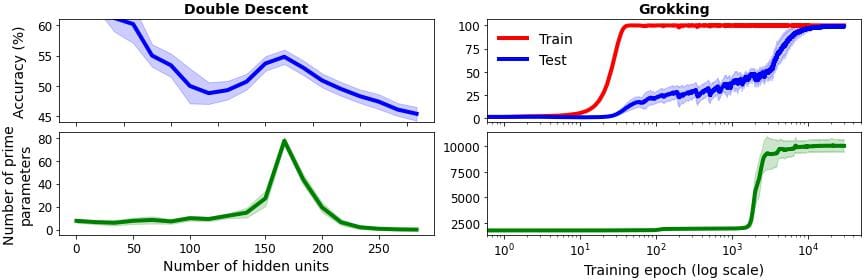
A recent position paper Jeffares and van der Schaar, 2025 argues that channeling your research (and the risk it entails) should be steered by an assessment of the potential value and downstream impact of the phenomena you target. Chasing narrow curiosities can be fun, e.g. the “Unified Theory of Double Descent[1] and Grokking[2] Through Prime Network Parameters” recreated by the authors (see below figure) may look novel on the surface, but its broader effect is minimal, decaying on merely fitting a narrow theory to the observed phenomena[3].
Double descent is a machine-learning phenomenon in which test accuracy rises at first as the model fits the data (first ascent), falls when overfitting sets in, and then climbs again in the heavily over-parameterized regime (the second ascent). ↩︎
Grokking is when a network reaches near-perfect accuracy on the training set early on yet continues to generalize poorly. If training is pushed far beyond this point, the test accuracy undergo a sharp rise and the model ultimately exhibits strong generalization long after overfitting first appeared. ↩︎
Interestingly, the authors in the paper describe how that prime numbers echo the phenomenon, but only in a limited sense and without displaying its broader effects. ↩︎
Impactful research scales: it carries predictive or design insights across domains and models. Curiosity-driven science has its place, is fine, yet engineering that matters, work that truly moves humanity forward, demand an explicit bet on value.
A multiscale optimization landscape
So the challenge of maximizing “potential research value” is not just about where (across AI’s subfields) or what (phenomena) to study. Framing the search also in terms of When (e.g, the timing of resources) and How (the set of resources) captures the essence of a highly dynamic discipline.
No need to wade into decision theory here, though I do wonder how best to formalize this type of search, as disruptive innovations come as avalanches filled with uncertainty.
Let’s map the territory. My approach has been to focus on sampling the multiscale structure of the AI landscape itself. Hierarchy is a practical tool.
In AI, abstraction comes in the form of “information”, surfacing in types as varied as time series, images, audio, text, or relational/tabular data. These naturally line up with subfields like NLP, computer vision, audio analysis, generative models, etc.
But signals are always more than their raw input. They travel through multiple abstraction layers:
- Data representation: How raw observations are encoded and structured.
- Model architecture: Especially in deep learning, each stack of layers synthesizes progressively richer abstractions.
- System organization: Practical deployments range from embedded AI at the edge to global cloud infrastructure.
- Hierarchical intelligence: AI landscape spans everything from narrow, task-specific automation to broad, collaborative learning. At each level, new forms of adaptation, memory, or autonomous decision-making emerge.
Plotting questions against hierarchy helps to identify how results might cascade.
Perspective
Zooming into this space, mapping signals, subfields, and techniques across branches, yields a navigable landscape.
But choosing a lane is ultimately a statement about how you handle uncertainty.
It’s the statement of your vision. So, What’s Your Bet?
References & further reading
- Epoch AI training-compute dataset – https://epoch.ai/data/large-scale-ai-models
- Not All Explanations for Deep Learning Phenomena Are Equally Valuable https://arxiv.org/abs/2506.23286
- Lamport, Uncertainty – https://cacm.acm.org/opinion/uncertainty/
- Lampson, Abstractions – https://cacm.acm.org/opinion/abstractions/
- LLM challenges survey – https://arxiv.org/pdf/2402.06196
- Sebastian Raschka, LLM Research Papers 2025 – https://magazine.sebastianraschka.com/p/llm-research-papers-2025-list-one