


I’ve been building distributed systems for a long time. I was on the engineering team for Microsoft’s Azure and later, as CTO at Easygo, ran massive sites like Kick where we were held to some of the highest SLAs in the industry. Across all those years, one lesson was burned into my mind: the easy emergencies are the full outages.
The hardest page to respond to was always the one where we weren't in a full outage, but a partial one. The ones where P99 latency is through the roof, users are getting intermittent errors, but every pod is green. The ones where you know something is deeply wrong, but you don't know why.
These are gray failures (Huang et al. 2017), and they expose a fundamental disconnect in how we manage modern systems.
From Step-Functions to Continuous Systems: Why Rules Fail
Think about how we automate operations today. Our solutions are overwhelmingly rule-based: IF CPU is over 80% for 5 minutes, THEN add a node. IF an endpoint fails 3 health checks, THEN restart the pod. These rules create a behavior pattern that looks like a stepwise graph, a series of rigid, discreet reactions.
Yet, live distributed systems don’t behave that way. Their failure modes are fluid and complex, a cascade of interdependent variables that look much more like a continuous function. They produce emergent behaviors that a simple set of IF/THEN rules can’t possibly capture (Zhang, Qu & Chen 2025).
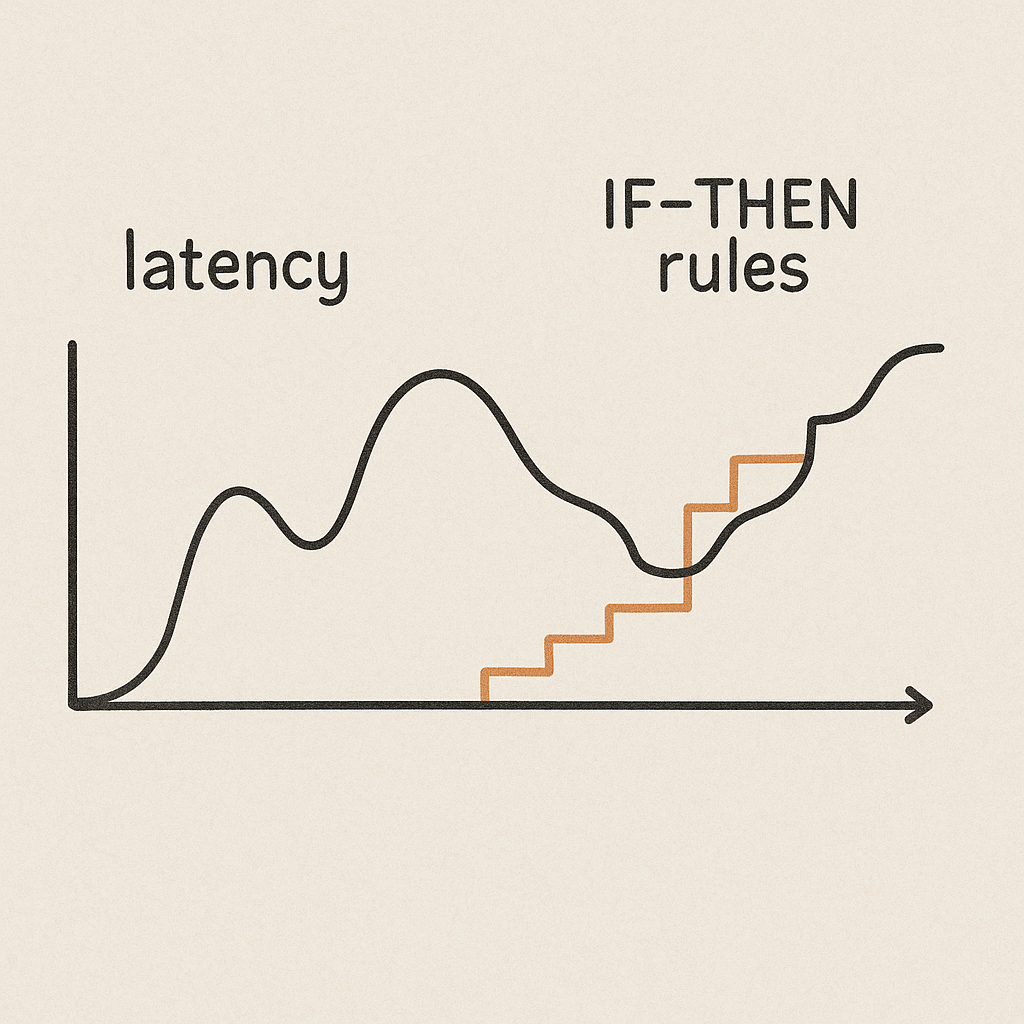
When you overlay a stepwise solution on top of a continuous problem, the results are clumsy at best. My intuition has long been that we might be better off replacing, or at least augmenting, these rigid rules with trained models. What if a deep learning model could understand the emergent behavior of a failing system and predict a gray failure before it happens?
To do that, you need data. And before you can get data, you need a lab.
The Problem: We Need a Better Lab
To explore this idea, we need to generate high-fidelity data that captures the nuances of failing systems. Canonical benchmarks like DeathStarBench (Gan et al. 2019) are a great place to begin, but they don't truly provide the rigorous experimental environment we need. To train a model, you can’t have noise and instability in your data; you need controlled, repeatable experiments that can explore the entire problem space.
Specifically, we realized we needed an environment that was topologically aware, allowing us to treat the application architecture itself as a key experimental variable (Bagheri, Song & Sullivan 2009).
Designing a True Experiment
This led us to a new way of thinking, centered on a few key principles:
- Isolate the Platform from the Experiment: An experiment needs a clean, consistent starting point every single time.
- Treat Application Topology as a Variable: The shape of the application is not a constant; it's a variable to be tested.
- Define Experiments Declaratively: The entire experimental setup, the topology, the failure to be injected, and the metrics to be gathered, should be captured in a single, version-controlled file.
Conceptually, this allows us to frame a hypothesis in a configuration file:
# A declarative approach to defining a resilience experiment
# Hypothesis: A "gen3" architecture will show CPU pressure
# in its upstream services when the social graph is latent.
topology: "gen3-disaggregated"
# (This references a definition of a fine-grained microservice architecture)
chaos_injection:
type: "network-latency"
target_service: "social-graph-service"
parameters:
delay: "200ms"
jitter: "50ms"
This declarative model is the foundation. It transforms ad-hoc testing into a systematic, scientific process for generating the clean data a future ML model would need for training.
Measuring the Full Picture
Of course, the data itself has to be rich enough. To capture the signature of a gray failure, you need to see the entire picture, correlating what the user experiences with the resource "cost" inside the system.
This means collecting metrics from multiple layers simultaneously:
- Client-Side: The user-facing latency and error rates.
- Infrastructure Cost: The CPU and memory impact on every container.
- Application Behavior: The propagation of requests through distributed traces.
- Mesh-Level: The work being done by the service mesh to compensate.
By observing all these signals, you can move beyond "it got slow" to a rich, high-dimensional dataset that truly represents the state of the system under stress (Narapureddy & Katta 2024).
The Real Goal: A New Class of Questions
When you combine a declarative experimental design with comprehensive measurement, you're doing more than just testing software. You are building a data-generation engine.
This allows us to ask the architectural questions we need to answer today, like whether a gen1 or gen3 topology is more resilient. But more importantly, it paves the way for the questions we want to answer tomorrow. We are building the framework to create the datasets that might one day train a model to finally understand the continuous, emergent, and often frustrating nature of gray failure.
Huang, P., Guo, C., Zhou, L., Lorch, J. R., Dang, Y., Chintalapati, M., & Yao, R. (2017). Gray failure: The Achilles’ heel of cloud-scale systems. In HotOS ’17: Proceedings of the 16th Workshop on Hot Topics in Operating Systems (pp. 1–6). ACM.
Zhang, J., Qu, Q., & Chen, X. (2025). Understanding collective behavior in biological systems through potential field mechanisms. Scientific Reports, 15, 3709.
Gan, Y., Zhang, Y., Cheng, D., Shetty, A., Rathi, P., Katarki, N., Bruno, A., Hu, J., Ritchken, B., Jackson, B., Hu, K., Pancholi, M., He, Y., Clancy, B., Colen, C., Wen, F., Leung, C., Wang, S., Zaruvinsky, L., Espinosa, M., Lin, R., Liu, Z., Padilla, J., & Delimitrou, C. (2019). An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems. In Proceedings of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’19) (pp. 3–18). ACM.
Bagheri, H., Song, Y., & Sullivan, K. (2009). Architecture as an independent variable (Technical Report No. CS-2009-11). Department of Computer Science, University of Virginia.
Narapureddy, A. R., & Katta, S. G. (2024). Observability with neural embeddings: Analyzing high-dimensional telemetry data using LLMs. International Journal of Advanced Research in Engineering and Technology (IJARET), 15(6), 58–75.