


A model, once you stop thinking of it as math and start thinking of it as a machine, is a dataflow. The weights stream in once and then sit still, the key and value for every token pile up and get read again by every token that follows, and the activations move from a projection into attention into a mixture of experts and back into the residual while a small sum runs between the GPUs so each one ends up holding the whole answer. Serving a model is really just moving those tensors along a path, a few hundred times a token and a few thousand tokens a second, for as long as the machine is on.
We spent the first stretch of this work making that path short in software, which is what the last post was about. We took the runtime out and drove the GPU through the kernel interface directly, and the little all-reduce that tensor-parallel decode runs on every token settled onto what looks like the floor of the fabric, around twenty microseconds, from a single host thread. That came from taking overhead away rather than adding cleverness, and once you've lived in that mindset for a while you start to look at the rest of the box the same way.
The thing that caught us off guard is how little the host does once the model is running. The runtime runs the decode loop on the GPU itself, so after setup the host opens the device, rings a doorbell, and waits. The weights are in HBM, the cache lives in HBM and moves between the GPUs, and the per-token sum happens on the GPUs. The processor a server is built around barely touches a tensor.
That left us with a question we hadn't expected to be asking, which wasn't how to wring more out of the general-purpose servers we already run, but what a machine designed for nothing but this dataflow would look like.
The machine the dataflow wants
Lay the four jobs of a serving node out in the order the tensors meet them. The host sets the work up. The fabric carries the weights and the cache to and between the GPUs. The GPUs do the math. The network ships cache out to the next machine when a long context is spread across several of them. In the servers everyone buys, the processor sits in the middle of that picture and everything else hangs off it, because the design assumes the CPU is where the data lives and the accelerators are things it hands work to. For the way we serve, that middle is mostly empty, so the natural thing is to turn the picture around, put the GPUs and the fabric in the centre where the data actually is, and leave the host off to one side doing its small setup job.
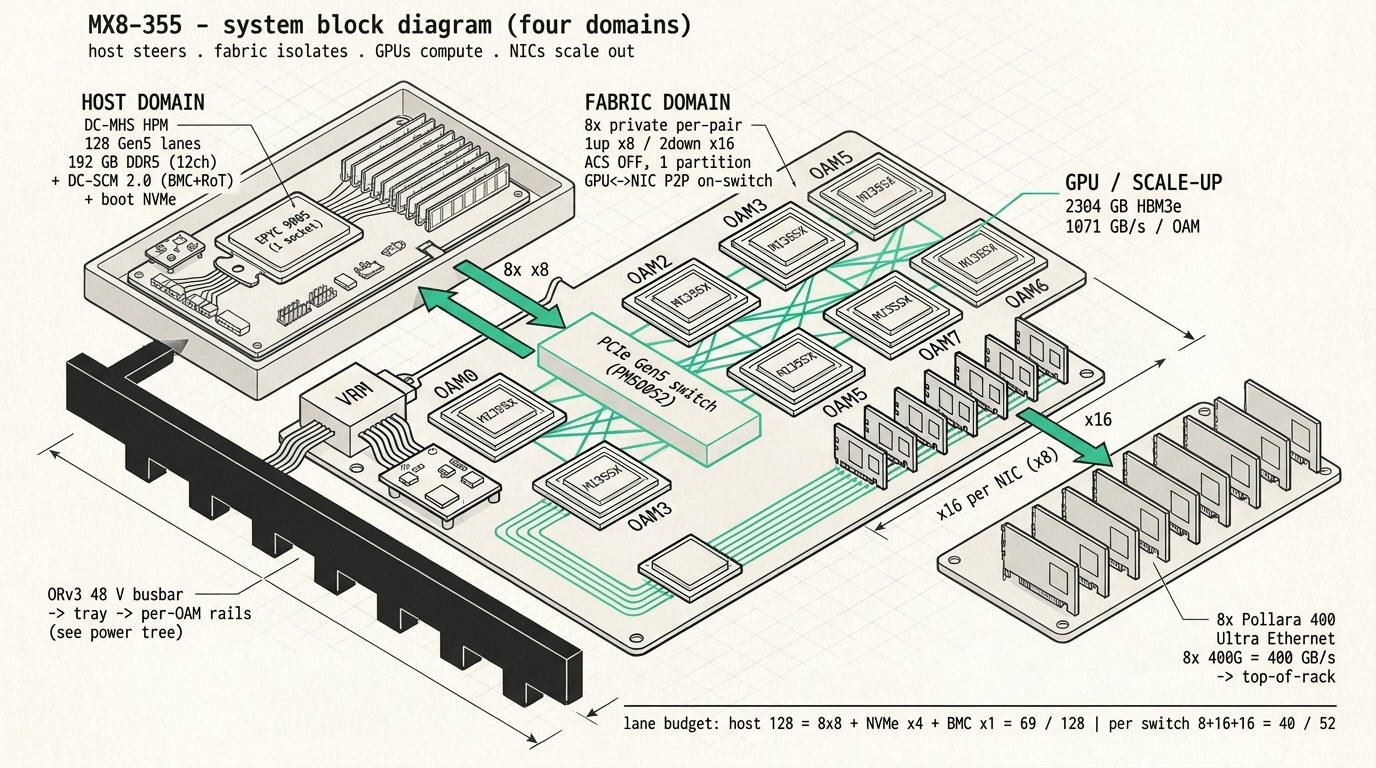
Turn it that way and a surprising amount of what makes a general-purpose server stops earning its keep. The second CPU was there to hold a working set the tensors never visit, the big bank of DRAM was there for the same reason, and the shared switch was there to fan one host's lanes out to a crowd of cards. None of that is wasted in a machine that has to be ready for anything. In one that only ever serves inference it's all weight you're carrying for nothing, and the room it frees up goes straight back into the parts that actually move tokens.
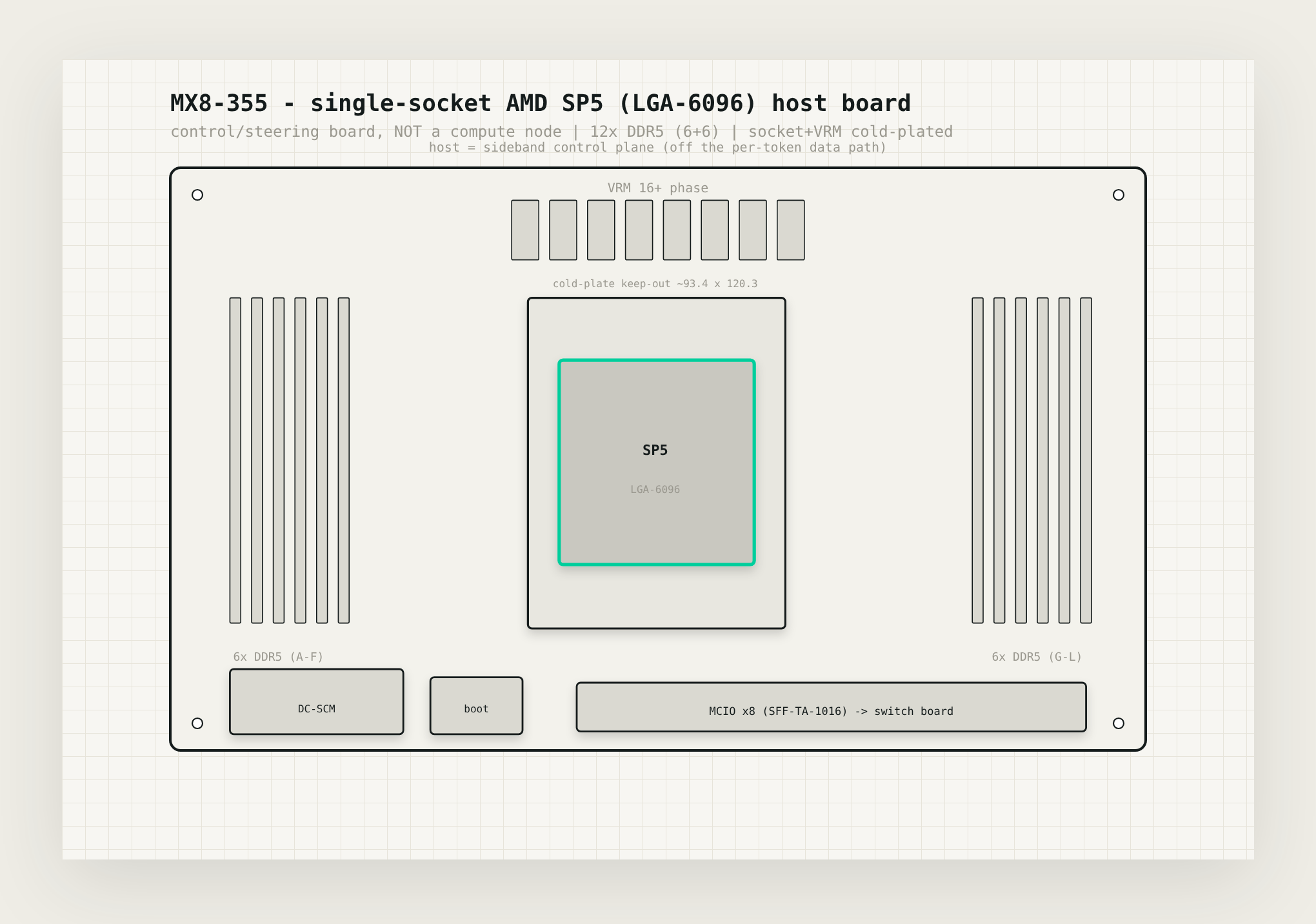
The MX8-355
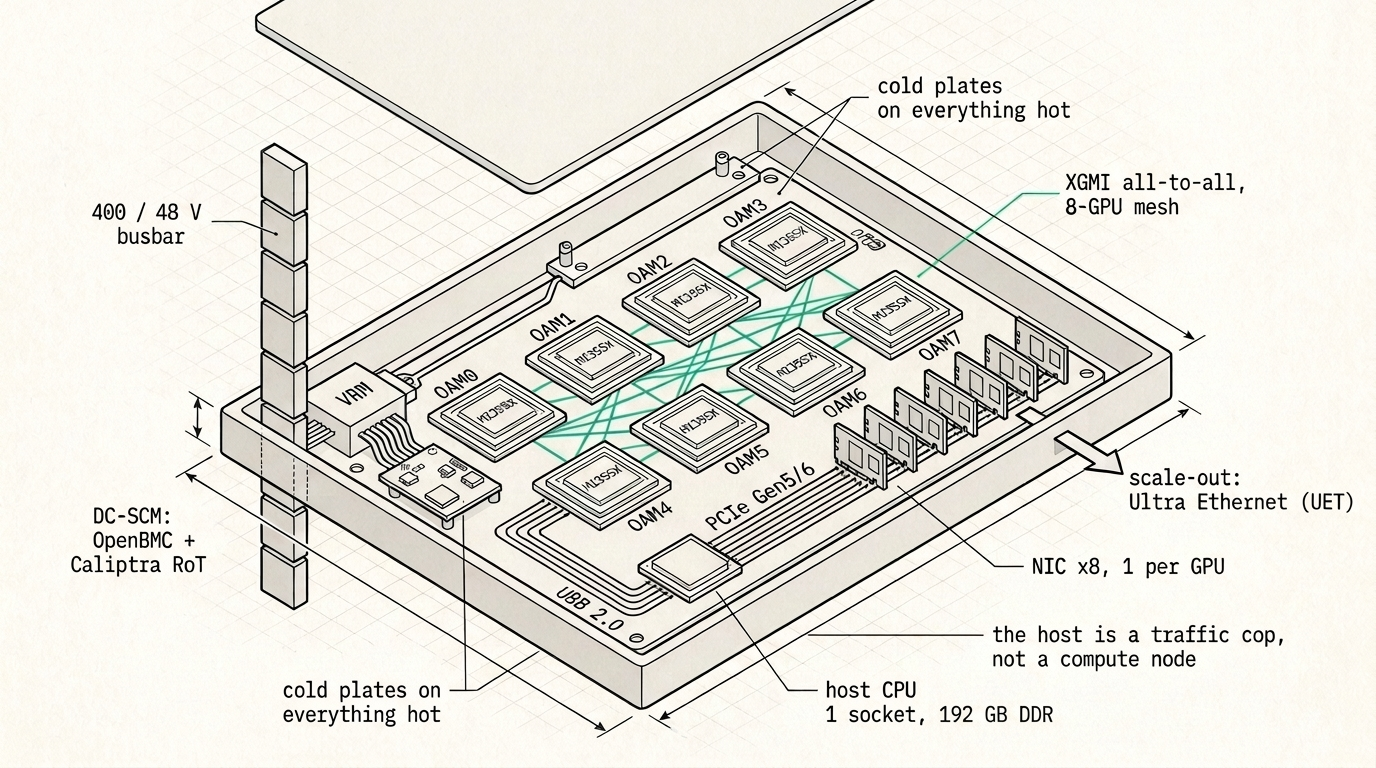
The MX8-355 is a single tray carrying eight AMD Instinct MI355X on a standard OCP baseboard, which comes to 2304 gigabytes of HBM, enough to hold a trillion-parameter mixture-of-experts model in low precision and still keep a long context in memory next to it. It's cooled by liquid straight to the chip, because a fourteen-hundred-watt part isn't something you cool with air at any density worth having, and a rail that runs flat out can't afford a chip that quietly throttles. It sits in an Open Rack v3 frame and takes three rack units.
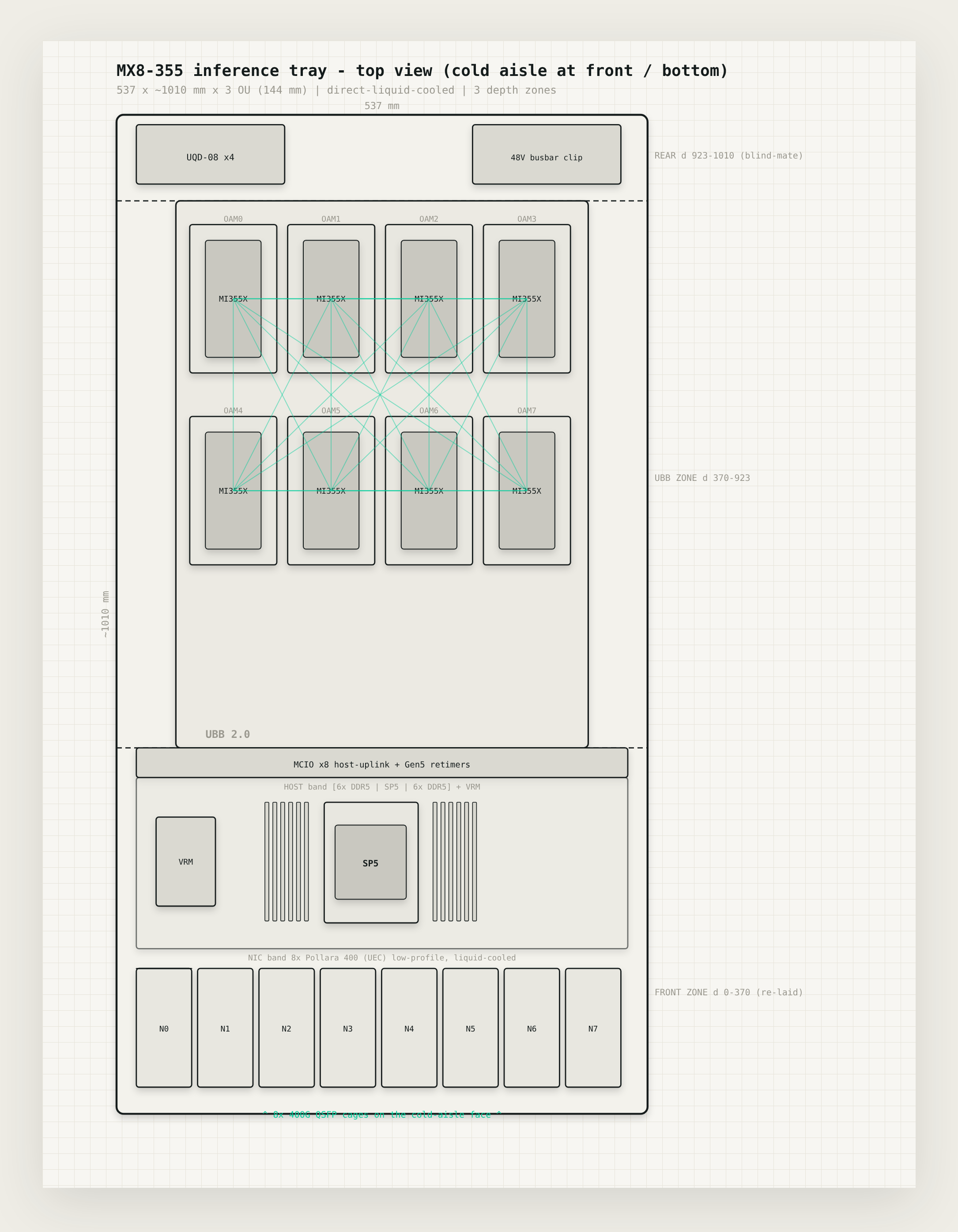
The part we find most interesting is how each GPU reaches the network. Every GPU gets its own network card on its own little switch, sharing it with nothing else, with the isolation feature a multi-tenant cloud needs simply switched off, so the card can write straight into GPU memory instead of detouring up to the CPU or waiting behind seven other GPUs on a shared crossbar. We had this slightly wrong at first and would rather say so. The trick isn't no switch at all, because two cards on a PCIe tree always have to meet at something above them, and a little switch dedicated to a single GPU and its card turns out to be the best arrangement there is. What matters is that the switch is private and quiet instead of shared and busy. We've started calling it the register-to-wire rail, because a value runs from a register on the GPU out to the wire of the network on a path that's its own the whole way, which is about as short as that trip gets.
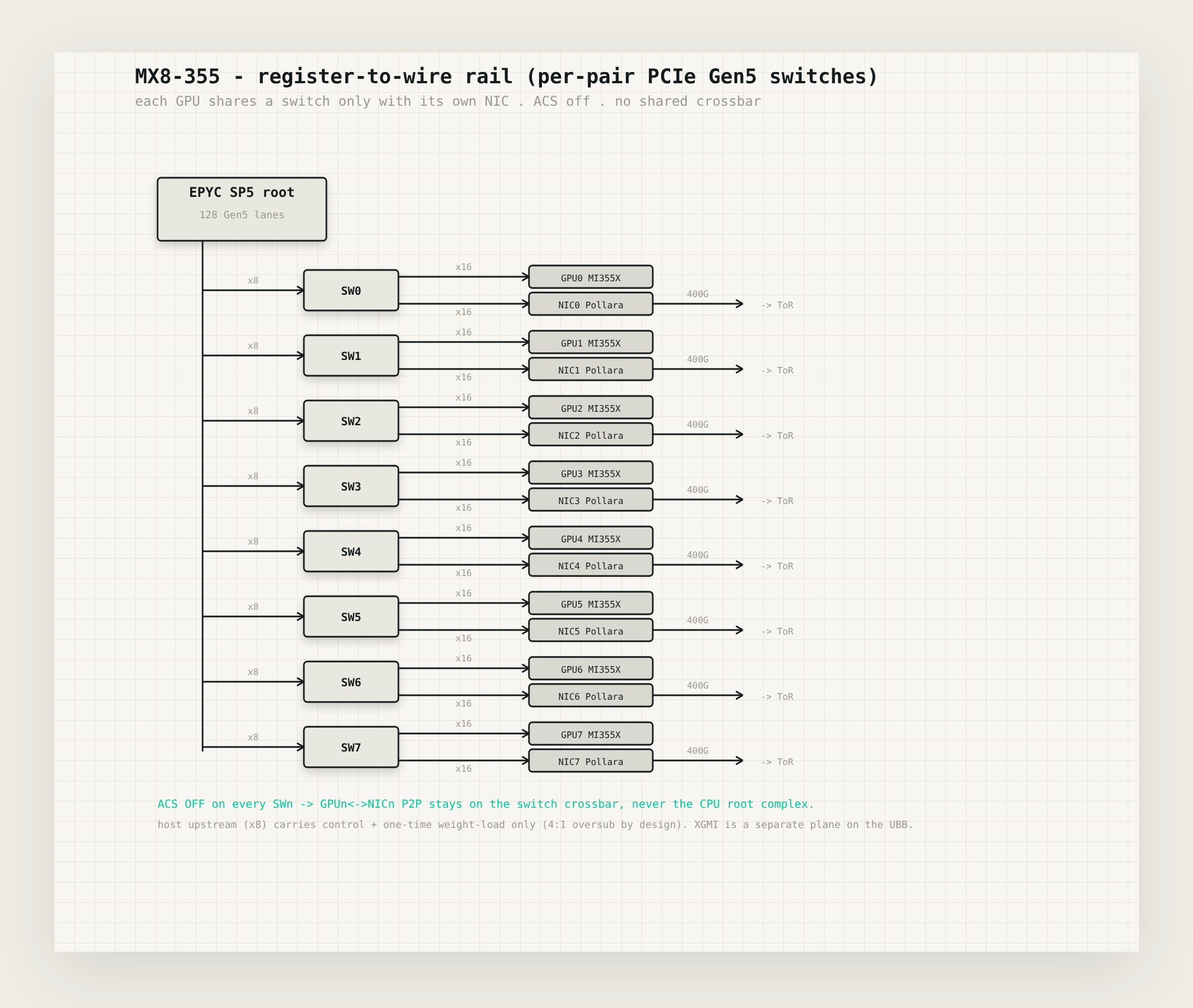
The host, meanwhile, comes back down to what it really does. One modest processor, enough memory to stage a weight load, a single boot drive. It brings the machine up, streams the weights into HBM once, keeps the network cards fed, and otherwise stays off the path the tensors travel.
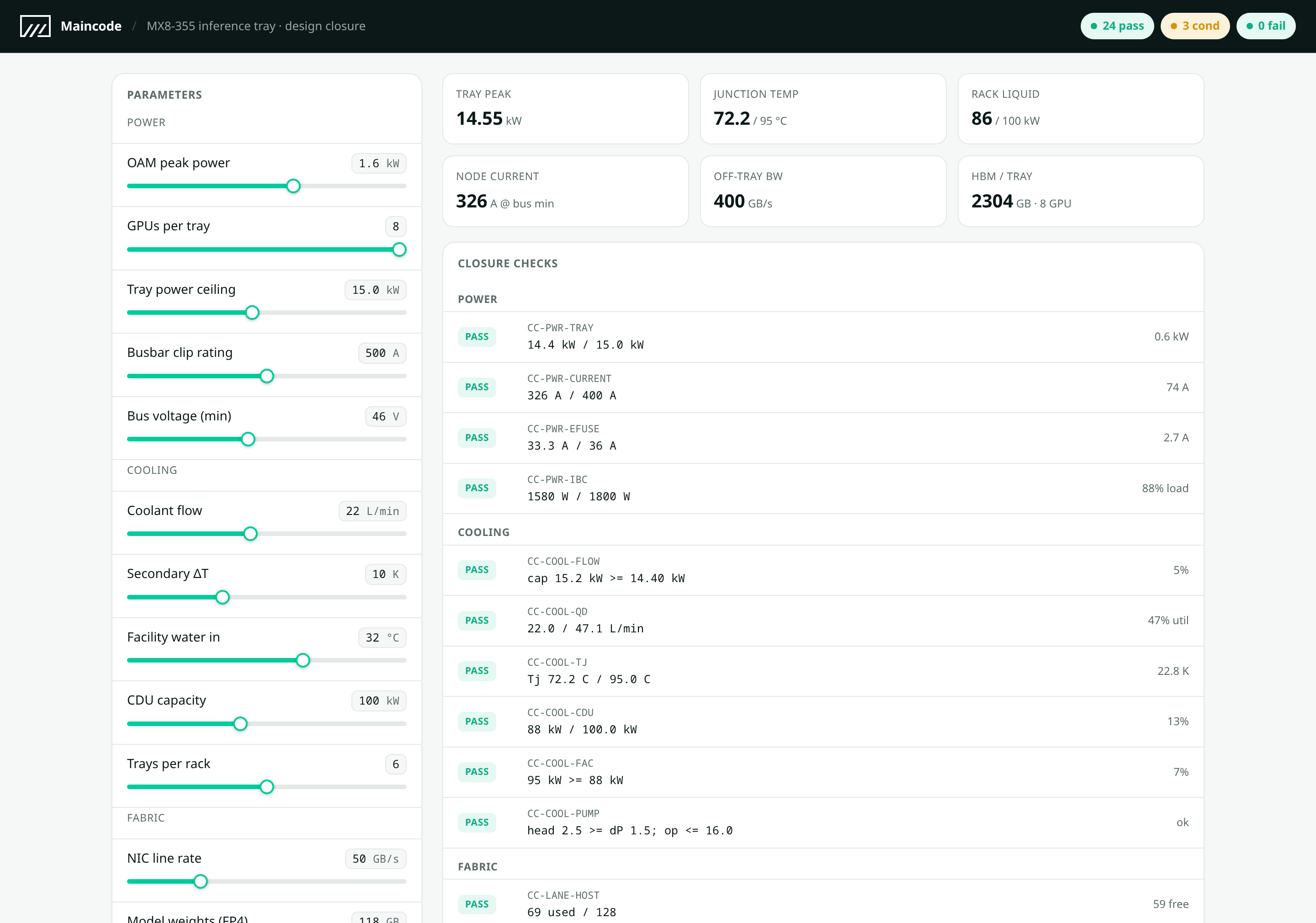
Checking the numbers
The numbers have to actually hold together, so we wrote a small program that rebuilds the whole machine from one set of constants and checks, one line at a time, that they do. The power adds up, with the tray pulling about fourteen and a half kilowatts at its peak under a fifteen-kilowatt budget and the current sitting well inside the busbar clip. The cooling carries the heat away at the flow we have, the hottest junction landing near seventy-two degrees against a limit of ninety-five, and a rack of six trays staying under its hundred-kilowatt cooling unit. The lanes balance, and the tray fits the rack by weight and by depth. Twenty-seven checks in all, and the three that come back conditional rather than a clean pass are two fabric bandwidths we're still taking from vendor figures and a cooling energy-balance that needs sensors we haven't specified yet.
We're sharing that program too, for the same reason we shipped the software as a container anyone could run. It's a few hundred lines with nothing to install, so if a number looks off you can open it, change the one you doubt, and see what moves. We'd rather you checked it than took our word for it.
There's a browser version as well, the same checks behind a row of sliders, so you can drag the OAM power or the coolant flow and watch every margin move with it.
It runs the same way the kernel work shipped last time, as a container you bring up with one command on your own machine.
docker run --rm -p 8080:8080 maincodehq/mx8-355-calculatorThen open http://localhost:8080 and start pulling the design apart.
Where this goes
It's a design and a stack of calculations, not a machine we've built and measured. The figures come from vendor data and our own arithmetic, and a few of the dimensions still wait on drawings we haven't been handed. The question we actually care about, whether a tray like this serves tokens more cheaply than the machines we run today, is one only a built tray and a real measurement can settle, and that's the part we're most curious to find out. We're working with the hardware that exists now, and trying to draw each layer so the same ideas carry onto the next generation rather than starting over.
We keep coming back to how little there is between a tensor and the silicon once you design for the dataflow instead of around a processor, and the MX8-355 is our first real attempt to follow that thought all the way down into hardware. For now it's a concept. A lot of what we're doing at this stage is learning how to think about a project like this at all, how you design a machine at this level, and how you work with a manufacturing partner like Foxconn to turn a paper design into something you can actually build. That's new ground for us, and a good part of what makes it interesting. We'll keep sharing what we find as we go, the dead ends as much as the parts that work.